


IITP, ‘인공지능 기술 청사진 2030’ 가이드 발간
[아이티데일리] 인공지능 기술 및 제품이 하루가 다르게 개발 공급되고 있다. 또한 관련 시장 및 산업도 빠르게 확산되고 있다. 인공지능 기술은 이미 일상생활 속으로 알게 모르게 빠른 속도로 파고들고 있는 것이다. 그러나 일반인들은 개념적으로는 이해하고 있지만, 인공지능이 어떤 분야에 어떻게 적용되고 있고, 어떻게 발전해 나갈지 등에 대해서는 잘 모르고 있는 게 현실이다. 또한 이와 관련된 믿을 만한 자료는 물론 청사진도 없다고 할 수 있다. 정보통신기술평가원(IITP)이 이에 대한 가이드를 최근 ‘인공지능 기술 청사진 2030’이라는 제목으로 발간해 주목을 받고 있다. 이 가이드는 1년여에 걸쳐 100명 이상의 인공지능 전문가들을 통해 연구 개발했다고 한다. 이 자료는 인공지능 기술 발전의 이정표 역할을 하기에 크게 부족함이 없다는 평가를 받고 있다.
‘인공지능 기술 청사진 2030’은 크게 다섯 가지 방향을 중심으로 추진했다고 한다. 즉 첫째, 사람의 지능과 유사한 기술 분류체계 수립에 심혈을 기울였다는 것이다. 다시 말해 IQ(지능지수), EQ(감성지수) 같은 사람의 지능을 반영할 수 있는 분류체계를 수립해 인간과 가까운 지능체계를 수립했다는 것이다. 두 번째는 미국 중심의 동향에서 중국, EU, 일본 등으로 조사범위를 확대해 각국의 프로젝트 파악에 주력했고, 세 번째는 새로운 기술 분류체계를 기반으로 100여명이 넘는 인공지능 전문가들을 통한 심층 기술수준을 조사했으며, 네 번째는 일반인들도 쉽게 이해할 수 있는 기술 개요부터 전문가들이 원하는 국내외 동향과 주요 R&D 이슈를 폭넓게 조사 정리했다고 한다. 마지막으로는 실제 산업분야에 적용 가능한 인공지능 기술을 제시했다고 한다.
본지는 이에 따라 ‘인공지능 기술 청사진 2030’을 5회에 걸쳐 주요 이슈별로 요약 정리해 게재한다. 즉 ▲깊이 성장 AI ▲범위 성장 AI ▲지속성장 AI ▲신뢰성 있는 AI ▲공감하는 AI 등이다. <편집자>
① 깊이 성장 AI
② 범위 성장 AI
③ 지속 성장 AI
④ 신뢰성 있는 AI (이번호)
⑤ 공감하는 AI
개념 및 범위
개념
AI 모델의 판단 결과에 대한 신뢰성(trustworthy) 확보를 위한 기술로, AI 기술이 실 세계에 적용되기 위한 필수 기술로 평가된다. 세부적으로 판단 결과에 대한 설명 가능성(explainable), 적대적(adversarial) 공격에 대한 견고성(robustness), 성별 및 인종 등 특정 사회적 계층에 편향되지 않은 공정성(fairness)의 확보가 필요하다.
범위
AI 모델의 판단 결과를 사람이 신뢰할 수 있도록 판단 결과에 대한 설명성, 견고성, 공정성 확보 기술을 대상으로 함.
• 설명 가능한 AI
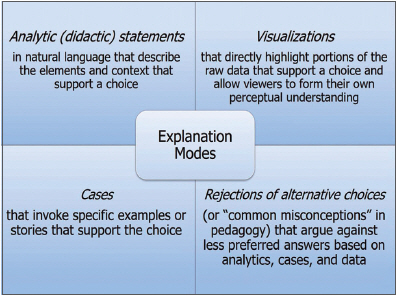
블랙박스와 같은 AI 모델을 분석하여 판단 결과에 대한 이유를 사용자가 이해하고 신뢰할 수 있도록 설명하는 기술이다, 딥러닝 모델 내부를 분석하여 판단 결과가 도출된 이유를 제시하는 기술, 판단 결과를 뒷받침하는 근거를 인식하는 기술을 포함한다.
• 견고한 AI
AI 모델이 오동작하면서 발생하는 문제점을 방지하고자 하는 연구로 AI 모델에 대한 취약성 연구와 AI 모델을 통해 데이터를 추출하거나 공격에 이용하는 것을 방지하는 연구를 포함하고 있다.
• 공정한 AI
특정 보호변수(인종, 성별, 지역 등)에 무관하게 AI 모델의 판단 결과를 제시할 수 있는 기술, 학습 데이터의 불균형으로 예측이 한 쪽으로 치우쳐 있더라도 데이터 불균형에 영향을 받지 않는 판단 결과 제시 기술을 포함한다.
주요 기술동향
• 설명 가능한 AI
딥러닝 기술의 발전으로 개별 태스크의 성능이 비약적으로 개선되고 있다. 이런 상황에서 실제 적용을 위해 블랙박스 형태의 인식 결과에 대한 설명가능성 연구가 최근 주요 연구 과제로 급부상하고 있다.
- Arxiv에 공개된 컴퓨터(CS) 분야 논문 중, 제목에 Explainable 키워드를 포함한 논문은 2015년 9건에서, 2016년 22건, 2017년 46건, 2018년 115건, 2019년 236건으로 매년 전년 대비 2배 이상의 증가하고 있다.
• 설명 가능한 AI 접근방법
설명 가능한 AI는 단일 접근방법이 아닌 다양한 유형의 접근방법이 연구되고 있으며, 주요 접근방법의 예는 아래와 같다.
▷입력 요인(Input Attributaion) 분석: 입력 부분과 출력 결과 사이의 딥러닝 모델 경도(Gradient) 또는 관련성(Relevance) 점수 분석을 통한 설명가능성 제시 방법으로, LRP, RAP, DeepLIFT, Guided Backprop, GradCAM 등의 방법 제안.
▷내부(Internal) 분석: 딥러닝 모델 내부 뉴런의 활성화 조건을 분석하는 접근 방법으로, Network Dissection, GAN Dissection 등의 방법 제안.
▷집중(Attention) 분석: 딥러닝 모델의 집중 매커니즘을 분석한 설명가능성 제시 접근방법으로, RETAIN, Saliency Maps 등의 방법 제안.
▷대리(Surrogate) 모델 분석: 설명가능성을 제시하는 대리 모델(Linear, Tree, 규칙 기반 등)을 학습하는 접근방법으로, LIME, SHAP, DeepRED, RULEX 등의 방법 제안.
• 견고한 AI
견고한 AI는 AI 모델이 오동작하면서 발생하는 문제점을 방지하고자 하는 연구로, 크게 AI 모델의 취약성 관점에서 AI 모델 공격 및 방어 기술, AI 모델을 통한 데이터 유출 및 공격 관점에서 AI 모델 정보 삽입/추출 기법으로 구분할 수 있다.
• 견고한AI - AI 모델 공격 및 방어 기술
AI 모델 자체에 내재하고 있는 한계 및 민감도를 이용하여 눈에 띄지 않는 잡음을 삽입하거나 일부 입력 정보를 조작함으로써 의도하지 않은 결과를 만들도록 하는 공격 기법과 이를 방어하기 위한 기술에 대한 연구. 예를 들어 아래 그림과 같이 “Panda”로 분류된 사진에 눈에 보이지 않는 미세한 잡음을 삽입하여 높은 정확도로 “Gibbon”으로 오분류 시키는 것을 AI 공격으로 정의함.

• 공정한 AI
AI 공정성은 자동화된 의사결정 프로그램의 편향적 결과를 보여준 사례들에서 부각된 이슈이며, 최근 3년간 주로 글로벌 IT 기업(IBM, Google, Facebook) 위주로 공정한 AI를 개발해 왔다. 주요 연구주제로는 공정성을 측정하는 Metric 설계, 분류 문제에서의 공정성 기준 마련이 있음.
• 공정성을 측정하는 Measure 설계
공정성 측정 지표는 일반적으로 예측에 대한 confusion matrix에서 제공하는 각종 지표를 활용하며, 문제에 적합한(problem-specific) 지표를 개발하는 방법이 존재.
• 분류 문제에서의 공정성 기준
예측 결과와 특정 정보가 무관한지의 여부를 판단하는 독립성(Independence), 주어진 정보에 대한 예측 결과와 특정 정보가 무관한지의 여부를 판단하는 분리성(Separation), 예측 결과에 대해 주어진 정보가 특정 정보와 무관한지의 여부를 판단하는 충분성(Sufficiency)이 있음.
