


버즈니 AI LAB 리서치 엔지니어 서지수

[아이티데일리] 1. 개요
이커머스의 발달로 온라인에서 많은 상품을 사고팔 수 있음에 따라 상품의 리뷰 수 또한 방대한 양으로 늘어나고 있다. 이커머스 관련 플랫폼에서는 수많은 리뷰를 가공해 사용자에게 더 쉽고 유용한 형태로 제공하고 있다. 연구자들은 리뷰를 분석하거나 리뷰를 작성하는 이용자의 유형을 분석하기도 한다. 또한 리뷰만을 분석해주는 서비스도 출시되고 있을 정도로 리뷰를 분석해 응용하는 것은 굉장히 중요해지고 있다.
버즈니가 운영 중인 모바일 홈쇼핑 플랫폼 ‘홈쇼핑모아’는 플랫폼 특성상 여러 홈쇼핑사의 상품 리뷰 정보를 모으고 이를 사용자에게 제공한다. 하지만 사용자에게 단순히 많은 양의 리뷰를 제공하는 것은 사용자에게 많은 불편함을 줄 수 있다. 볼 수 있는 리뷰의 양은 많지만, 찾고자 하는 정보를 일일이 확인하기에는 시간이 많이 소요되고 사용자에게 피로감을 줄 수 있다. 따라서 이를 해결하기 위해 버즈니만의 리뷰 분석 시스템을 구축하고자 했다.
현재 개발된 버즈니의 리뷰 분석 모델은 총 4가지로, △리뷰 랭킹 △리뷰 의견 추출 △리뷰 의견 그룹핑 △리뷰 의견 속성 분류 등이다. 각 문제를 풀기 위해 학습데이터와 모델을 어떻게 구축했는지 소개하고자 한다.
2. 리뷰 랭킹
2.1 목적
홈쇼핑모아는 여러 홈쇼핑사의 상품 리뷰 정보를 사용자에게 제공할 수 있다. 하지만 여러 홈쇼핑사의 리뷰가 축적되면 리뷰 양이 많아져, 사용자는 많은 리뷰 중 유용하고 정보가 많은 리뷰를 찾기 어려워진다. 따라서 정보가 풍부하고 유용한 리뷰를 상위에 노출시켜, 사용자가 양질의 리뷰를 먼저 볼 수 있도록 리뷰 랭킹 모델을 구축했다.
2.2 알고리즘
리뷰 랭킹을 하는 방법은 크게 2단계로 구성된다. 첫 번째 단계는 어떤 리뷰가 유용한지 기준을 정하고, 이를 점수화한다. 유용한 리뷰 기준은 아래 6가지로 구성된다. 또한 <그림 1>은 6가지 리뷰 유용성 기준을 예제와 함께 번호대로 설명한다.
(1) 이커머스 리뷰에서 상품에 대한 의견은 사용자가 생각하는 각 상품의 특징을 의미하므로, 의견이 많으면 많을수록 유용한 리뷰라고 정의한다. 이때 리뷰에서 의견을 추출하는 의견 추출기를 사용한다.
(2) 리뷰에서 다양한 내용과 많은 정보가 있을수록 유용한 정보라고 정의한다. 정보성을 수치화하기 위해서는 tf-idf를 사용하였다.
(3) 상품 리뷰의 이미지를 통해 사용자는 상품의 실제 모습을 확인할 수 있기 때문에, 이미지가 없는 리뷰보다 이미지가 있는 리뷰가 유용한 리뷰라고 정의한다.
(4) 해당 상품의 리뷰 평균 별점과 해당 리뷰 별점이 유사할수록, 상품을 일반적이고 객관적인 시각으로 상품을 평가했다고 정의한다.
(5) 최근 리뷰일수록 최근 상품에 대한 정보를 반영하고 있다고 판단하여 이를 더 유용한 리뷰라고 정의한다.
(6) ‘좋아요’ 수를 더 많이 받은 리뷰일수록 더 유용한 리뷰라고 정의한다.

두 번째 단계는 각 6가지 기준을 중요도에 따라 가중치를 조정하여 최종 점수를 만들고, 이를 통해 리뷰를 순위화한다.
2.3 서비스 적용
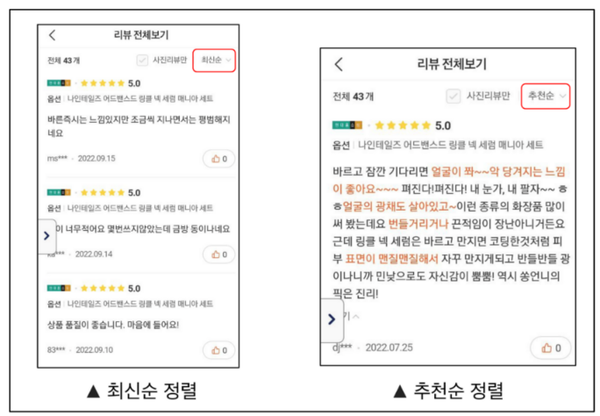
<그림 2>는 같은 상품 리뷰에 대해 정렬 방식만 바꿔 비교한 결과를 보여준다. 왼쪽 사진은 최신순으로 정렬한 것이고, 오른쪽 사진은 리뷰 랭킹 알고리즘을 통해 만들어진 리뷰 유용성 점수를 기준으로 정렬한 것이다. 이를 통해 최신순으로 정렬한 것보다 추천순으로 정렬했을 때 다양하고 정보가 많은 리뷰를 먼저 확인할 수 있음을 알 수 있다.
3. 리뷰 의견 추출
3.1 목적
리뷰 의견 추출 모델은 사용자가 작성한 리뷰에서 상품에 대한 의견/특징을 추출하기 위한 모델이다. 이 모델을 구축하고자 한 이유는 사용자가 상품에 대한 의견을 빠르게 확인할 수 있도록 리뷰 의견을 추출하여 하이라이팅하고, 각 상품의 특징을 추출하여 분석할 수 있도록 하기 위함이다. 이때 리뷰 의견 하이라이팅은 <그림 2> 내 주황색으로 표시된 부분처럼, 사용자가 상품에 대한 의견을 한눈에 볼 수 있도록 다른 텍스트 색이나 배경색을 사용해 이를 강조하는 것을 의미한다. 하지만 ML 모델이 이를 학습하기 위해서는 학습 데이터가 필요한데, 수동으로 레이블링하여 학습 데이터를 구축하기에는 오랜 시간이 걸린다. 따라서 반자동으로 학습 데이터를 구축하고자 한다.
3.2 반자동 레이블링 학습 데이터 구축
리뷰 의견 추출을 위한 학습데이터 구축에는 크게 2가지 기준이 필요하다. 하나는 어디서부터 어디까지 의견으로 볼 것인지이고, 다른 하나는 어떤 정보가 있어야 의견으로 볼 것인지이다. 즉 어떻게 의견 단위를 설정할 것인지, 어떻게 의견 여부를 결정/분류할 것인지에 대한 기준이 필요하다. 이 2가지 기준을 정의하고 이를 자동 레이블링으로 풀기 위해, 최종적으로 의견 단위는 구문 분석기를 통해, 의견 여부 결정은 형태소 분석기를 통해 자동화했다.
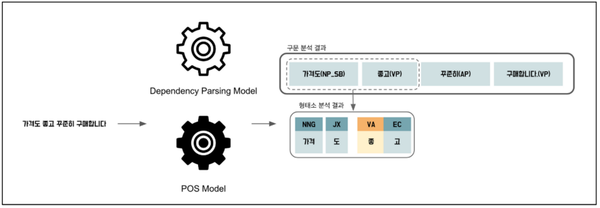
반자동 레이블링 방법은 6단계로 구성된다. [1단계]는 리뷰를 문장별로 쪼갠다. [2단계]는 리뷰 문장 별로 구문 분석과 형태소 분석을 한다. [3단계]는 구문 분석 결과 중 동사구를 의미하는 VP(verb phrase)를 기준으로 의견 단위를 나누는 것이다. <그림 3>은 “가격도 좋고 꾸준히 구매합니다”라는 문장의 구분 분석과 형태소 분석 결과를 보여준다. 구문 분석 결과를 이용해 “가격도 좋고 꾸준히 구매합니다”라는 문장을 VP를 기준으로 “배송도 좋고”와 “가격도 맘에 들어요”로 나눌 수 있다.
[4단계]에서는 각 의견 단위 텍스트 안에 의견 관련 형태소가 있는지 없는지 확인한다. 이때 의견 관련 형태소 리스트는 미리 정의되어 있어야 하며, 상품에 대한 평가나 특징을 의미할 수 있는 형태소를 말한다. 예를 들어 ‘좋(VA)’, ‘싫(VA)’은 의견 관련 형태소로 정의할 수 있다. 따라서 ”배송도 좋고”에는 의견 관련 형태소인 ‘좋(VA)’이 있으므로, 의견이라고 분류된다. [5단계]는 4단계까지 거친 자동 레이블링 된 학습 데이터를 확인하고, 후처리를 통해 잘 못 라벨링된 데이터들의 특징을 파악해 보완하거나 예외 처리를 한다.
이렇게 반자동 레이블링 된 학습 데이터는 사람이 직접 레이블링한 데이터보다 품질은 떨어지지만 많은 양의 학습데이터를 빠르게 구축할 수 있고, 태스크(task) 및 레이블링 기준을 정하는 초기 단계에서 유용하게 사용할 수 있다. 의견 하이라이팅과 상품 특징 분석을 위해 “단순한 긍/부정 의견(예 : ‘마음에 들어요~’)은 의견으로 배제한다”, “사연(예 : ‘방송하는 곳이 있으면 항상 구매해서 사용하고 있습니다’)은 의견으로 배제한다” 등 버즈니만의 의견 기준이 존재하는데, 처음에는 이 기준이 명확하지 않았기에 종종 바뀌었다. 의견 기준이 수정되면 학습 데이터 또한 수정된 의견 기준에 맞추어 재레이블링해야 하는데, 반자동 레이블링을 통해 후처리에서 이 수정된 기준을 반영하여 재검수없이 학습 데이터를 바로 구축할 수 있었다.
3.3 모델
의견 추출을 위해 BERT 기반 분류 모델을 적용하였다. 해당 모델은 토큰 단위로 B, I, O로 분류하는데, B는 Begin의 약자로 의견이 시작됨을 의미하고, I는 Inside의 약자로 의견이 이어지고 있음을 의미하고, O는 Outside의 약자로 의견이 아님을 의미한다. 예를 들어 모델 결과가 “가격도(B) 좋고(I) 꾸준히(O) 구매합니다(O)”이면 모델은 의견으로 “가격도 좋고”라는 하나의 의견을 추출한 것이다.
4. 리뷰 의견 그룹핑
4.1 목적
유사 의견 그룹핑 모델의 구축 이유는 한 상품 내 묶인 유사 의견 그룹 중 가장 크기가 큰 의견 그룹이 상품의 대표적인 특징으로 정의할 수 있기 때문이다. <그림 4>는 유사 의견 그룹핑 모델을 통해 그룹핑 된 의견 그룹 중 가장 크기가 큰 순서대로 나열한 것이다. 이를 통해, 해당 상품이 “향이 좋고 저렴하며 두께가 적당하다”는 정보를 알 수 있고, 이는 사용자가 직접 작성한 내용이기에 신뢰도도 크다. 이때 각 리뷰 의견들은 버즈니의 의견 추출 모델을 이용하여 추출된 것이다.

4.2 모델
현재 문장 임베딩으로 널리 사용되고 있는 SentenceBERT는 높은 품질의 문장 임베딩을 제공하고 오픈된 모델도 존재한다. 하지만 일반 문장을 학습한 SentenceBERT 모델은 상품 의견 그룹핑을 위해 사용하기에는 적합하지 않다. 예를 들어 “오랜 시간 사용해 봤는데 가격이 만족스럽다”라는 문장을 기준으로 “A.오랜 시간 사용해 봤는데 제품이 좋다”와 “B.가격이 만족스럽다” 라는 두 문장을 비교한다면, B 문장보다는 A 문장이 더 유사하다고 판단한다. 따라서 의견에 대해 잘 파악하도록, 리뷰 의견 데이터로 학습시켜 의견에 대한 표현 벡터를 만들고자 했다.
모델은 두 단계의 대조 학습을 이용하여 리뷰 의견에 대한 표현 벡터를 만들고, 이 벡터를 이용해 리뷰 의견을 그룹핑한다. 대조 학습은 데이터 증강 기법을 이용하여 레이블링 된 데이터없이 표현벡터를 학습할 수 있는 방법으로, 포지티브 샘플(positive sample)의 거리는 가깝도록 네거티브 샘플(negative sample)의 거리는 멀도록 학습시켜 표현벡터를 학습한다. 이때 기존 텍스트의 임베딩 벡터를 변환하는 데이터 증강 기법을 통해 포지티브 샘플을 만들고, 한 배치 내 다른 텍스트를 네거티브 샘플로 취급하여 학습시킨다.
버즈니에서는 ConSERT에서 착안한 모델을 두 단계 대조 학습을 통해 학습하는데, 첫 번째 단계는 자기지도 학습을 두번째 단계에서는 자동 레이블링을 통해 만들어진 학습 데이터를 이용해 지도 학습을 한다. 이를 통해 레이블링 된 학습데이터 없이 의견에 대한 표현 벡터를 만들고, 이 표현 벡터를 이용하여 그룹핑한다.
5. 리뷰 의견 속성 분류
5.1 목적
리뷰 속성 분류 모델은 사용자가 관심 있는 상품 속성에 대한 정보만을 뽑아서 제공하기 위해 개발되었다. 예를 들어 A라는 사용자는 상품의 가격과 관련된 정보만을 보고 싶은데, 이 정보를 확인하기 위해서는 눈으로 일일이 가격에 대한 정보를 찾아야 하다. 하지만 리뷰 속성 분류를 통해 해당 속성이 존재하는 리뷰만을 필터링하여 보여준다면 사용자는 원하는 정보를 편하게 확인할 수 있다.
5.2 모델
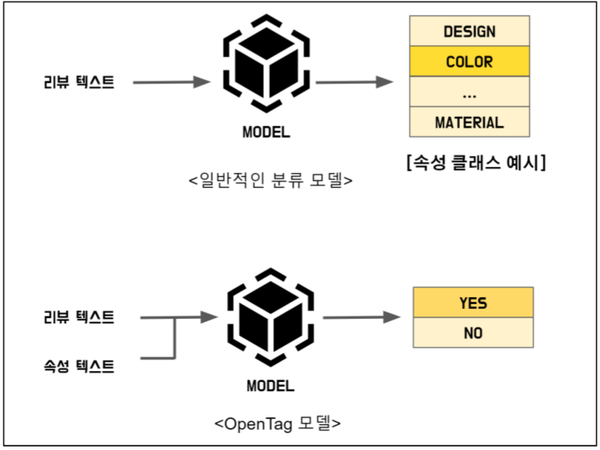
리뷰 의견 속성 분류를 위해 OpenTag 모델을 활용했다. <그림 5>의 일반적인 분류 모델의 경우, 분류하고자 하는 어떤 속성이 존재하는지 모델 내에 미리 정해주어야 분류할 수 있다. 따라서 분류하고자 하는 속성이 변경되면 모델도 변경해주어야 한다. 하지만 OpenTag 모델의 경우 입력으로 리뷰 텍스트와 속성 텍스트를 넣어주고 이 둘이 연관성이 있는지 없는지를 학습하기 때문에, 속성이 변경되어도 따로 모델 내부를 변경할 필요가 없다. 상품 속성의 경우 기술 발전 등에 따라 새로운 속성(예 : ‘폴더블 스마트폰’)이 생기기도 하고, 더 이상 의미가 없어 제거해야 할 속성이 존재할 수도 있다. OpenTag 모델은 이처럼 속성을 확장하거나 축소하기에 적합한 모델이라 판단하였고, 향후 자동으로 학습하는 프로세스를 구축하고자 하여 이 모델을 적용했다.
OpenTag 모델은 아래 4가지 장점을 가진다.
(1) 속성 확장/축소에 용이 : 새로 추가되어야 할 속성이 생기면, 일반적인 분류 방법은 모델을 수정하고 새로 추가된 속성의 학습데이터를 보강한 후 다시 학습시켜야 한다. 반면, OpenTag 모델을 사용하면 학습 데이터만을 추가로 학습시키면 된다. 즉 속성 tag에 대한 관리가 용이하다고 할 수 있다. 또한 향후 학습 데이터 자동 레이블링 방법을 구축하면, 학습데이터 구축부터 모델 학습까지 사람의 개입 없이 자동으로 학습하는 프로세스를 구축할 수 있다.
(2) 학습하지 않은 속성도 분류 가능 : 가격, 디자인 등 특정 속성이 아닌 속성 자체를 이해할 수 있으므로, 기존 분류 모델과 비교했을 때 학습하지 않은 속성에 대해서도 어느정도 예측 가능하다. 하지만 학습한 속성보다는 성능이 안 좋을 수 있다.
(3) 클래스 불균형 문제 완화 : 분류 문제에서 클래스 불균형 문제라고 하면, 클래스 별로 가지고 있는 데이터의 양의 차이가 큰 경우를 말한다. 이것이 문제가 되는 이유는 학습할 때 클래스 불균형이 크다면, 데이터의 수가 많은 클래스로 치우치게 예측하도록 학습이 되어 편향된 모델이 되기 때문이다. 하지만 OpenTag 모델에서는 속성에 대한 정보가 입력으로 들어가고, 클래스는 yes와 no로만 분류되기에 데이터의 클래스 불균형 문제를 완화할 수 있다.
(4) multi-label 분류 모델로 사용 가능 : 하나의 리뷰 텍스트는 여러 속성에 해당될 수 있는데 (예 : ‘디자인이 이쁘고 가격이 저렴해서 마음에 들어요’ → ‘디자인’과 ‘가격’ 속성에 해당), 이런 task를 여러 개의 라벨을 가질 수 있다고 하여 multi-label classification라고 한다. OpenTag 모델의 경우, 같은 리뷰 텍스트에 대해 2개 이상의 속성이 yes로 분류되면 해당 리뷰 텍스트가 여러 속성에 해당될 수 있으므로 multi-label 분류 문제를 풀 수 있다.
하지만 OpenTag 모델은 속성별로 예측해야 하므로, 속성 개수에 따라 일반적인 분류 모델보다 예측 속도가 느리다는 단점이 있다. 따라서 파라미터가 수가 적고 예측 시간이 짧은 모델 사용 등 속도 개선 방법을 고려해야 한다.
6. 결론
지금까지 리뷰 분석을 위해 개발된 모델인 리뷰 랭킹, 리뷰 의견 추출, 리뷰 의견 그룹핑, 리뷰 속성 분류 모델을 소개했다. 버즈니에서는 사용자에게 유용한 정보를 편리하게 찾을 수 있는 기능을 제공하고 리뷰 분석을 통해 상품을 분석해 점진적으로 리뷰 분석 모델을 개발했다. 앞으로 각 모델을 서비스에 녹이면서 보완할 점을 찾고 이를 개선해야 하는 도전 과제를 가지고 있다. 또한 서비스에 필요한 추가적인 리뷰 분석 시스템을 꾸준히 개발하고자 한다.